迁移学习的一些介绍
迁移学习其实就是当我们要做的target数据量不够多的时候,我们就可以用其他相关的target来训练我们的机器做这个target。
迁移学习分类可以分为下面四种:
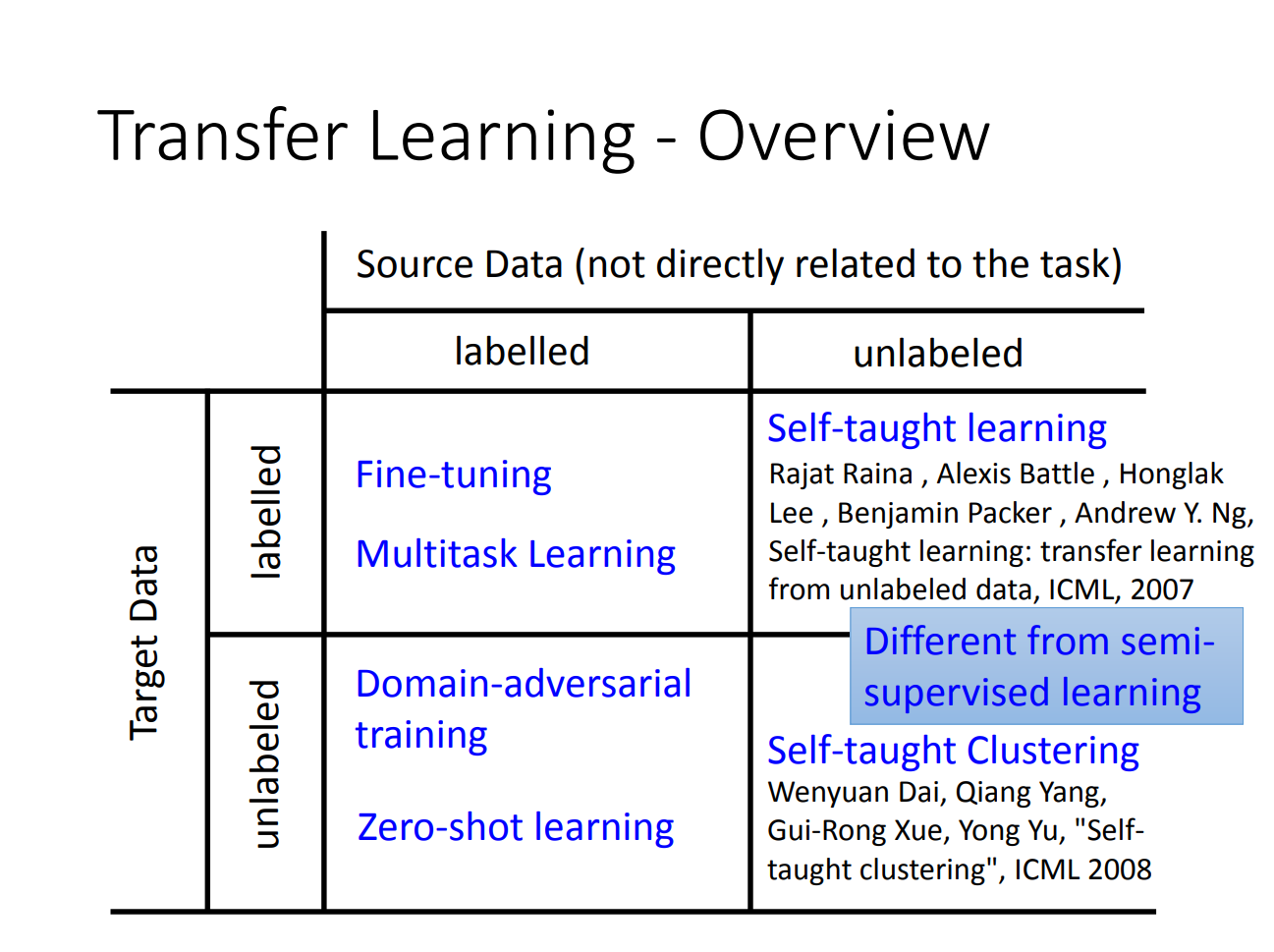
那实际上,一般来说,迁移学习是用源数据和源目标来学习目标域的函数。这fine-tuning说起都不能算是transfer learning。不过不同分类影响不大。
fine-tuning其实是一种非常简单的做法,比如说我们现在要做一个分辨马和驴的分类器,同时我们手上有一个训练好的猫和狗的分类器,那么我们就可以用猫和狗的分类器学会的隐藏层来微调学习分辨驴和马。
那做这个叫conservation learning,实现上就是将训练好的source network里面的参数来做初始化,然后用target data训练整个网络。但是这里的要求是,新训练出来的network跟原来source的network不要差太多。不要差太多的意思就是parameter不要差太多,另外同样的input,output也不要差太多。某种程度上,旧的network是新的network的regularization。
那实践上就是做layer transfer。当target数据很少的时候,就将所有的参数都迁移过来,然后固定住一部分的参数不变,重新训练没有被固定住的隐藏层。如果数据量够大,也可以学所有的layer。
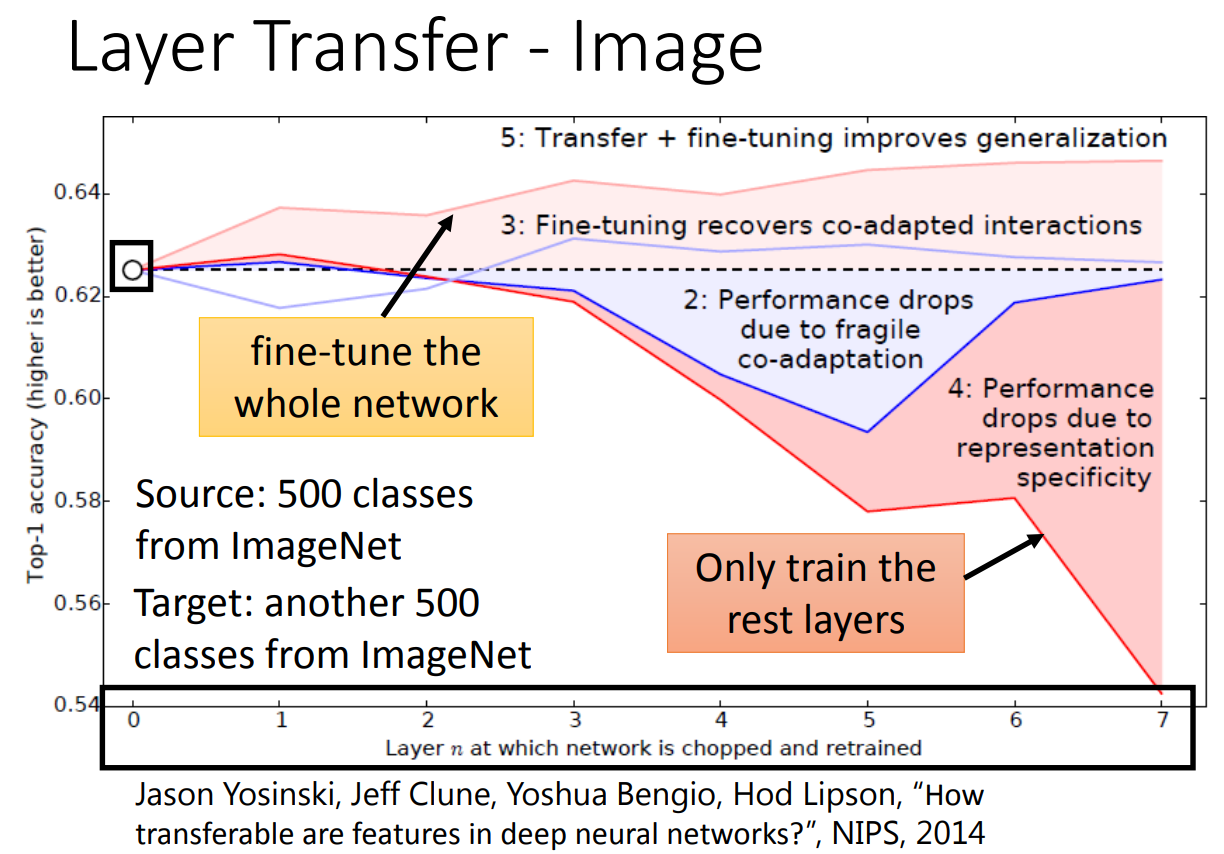
那不同的场景做layer transfer也不太一样。在语音识别上,一般是copy最后几层layer,因为最后输出的文字都是类似的。在图像上一般是copy前几层layer,因为卷积一开始就是去找某种隐藏的模式,不同的图片都可以找类似的模式。这一点可以参考一下之前的卷积网络,可以看到前面几层卷积就是找色块啊,形状什么的。
那实际上在图像上的训练效果:
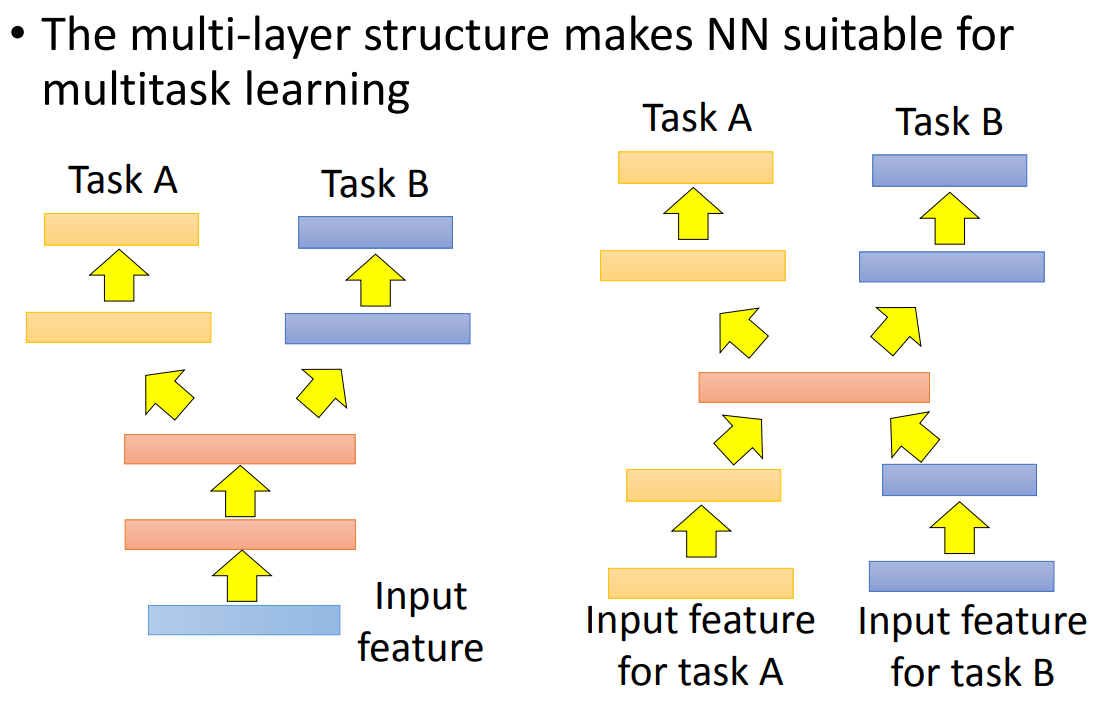
还有一种transfer是做multitask learning。那multitask learning在实践上,有可能是同样的数据做不同的task,也可能是不同的数据做不同的task。网络设计大概就是:
在机器翻译上,如果用左边的那个网络架构,同时混杂各种语言,然后做多个task,实验证明比单个语料的模型效果要好。
还有一种做法是progressive neural network,这个看上去很像RNN。
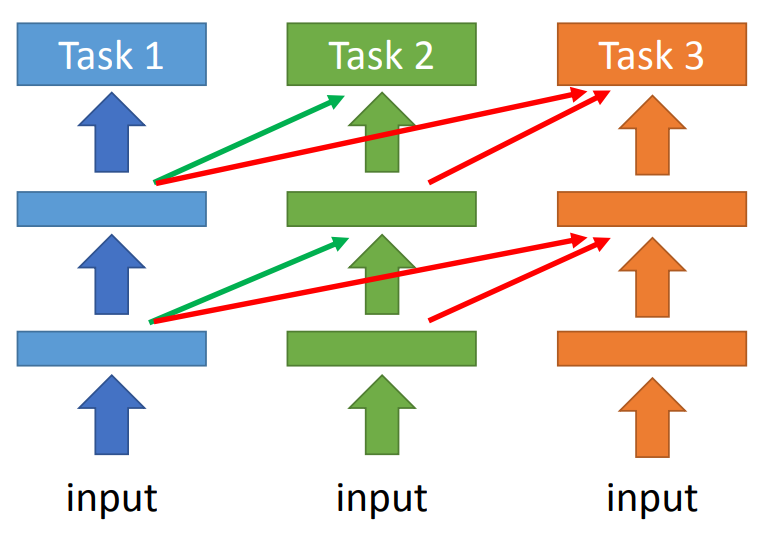
这个网络就是将之前的task的output作为下一个task的input来一起训练,这样可以避免每个task训练的时候完全遗忘掉之前学习的结果。
上面的source data和target data都是labeled的数据。那如果现在target data是unlabeled的,有两种学习方法,一种是domain adversarial learning,domain adversarial在设计的时候有两个目标,一个目标是构造一个feature extractor使得一个domain classifier无法分辨这个数据是来自target还是source,这样就能把二者的feature做到接近。另外一个目标就是同事要保证抽取出来的feature可以正确分类source data。做这个限制的原因是,如果不做这个限制,那么feature extractor把所有的feature全抽成0,那么domain classifier就完全无法区分了。
所以结构上设计为:
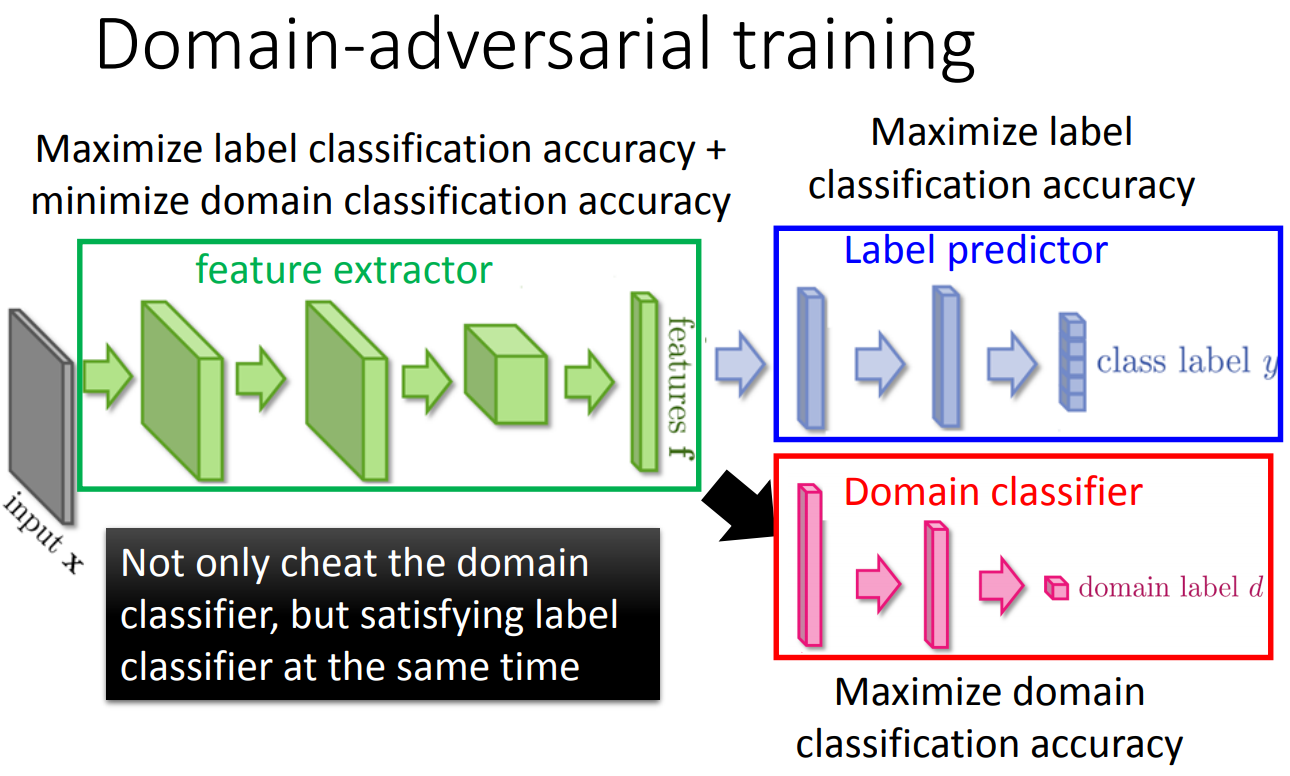
在训练的时候就是:
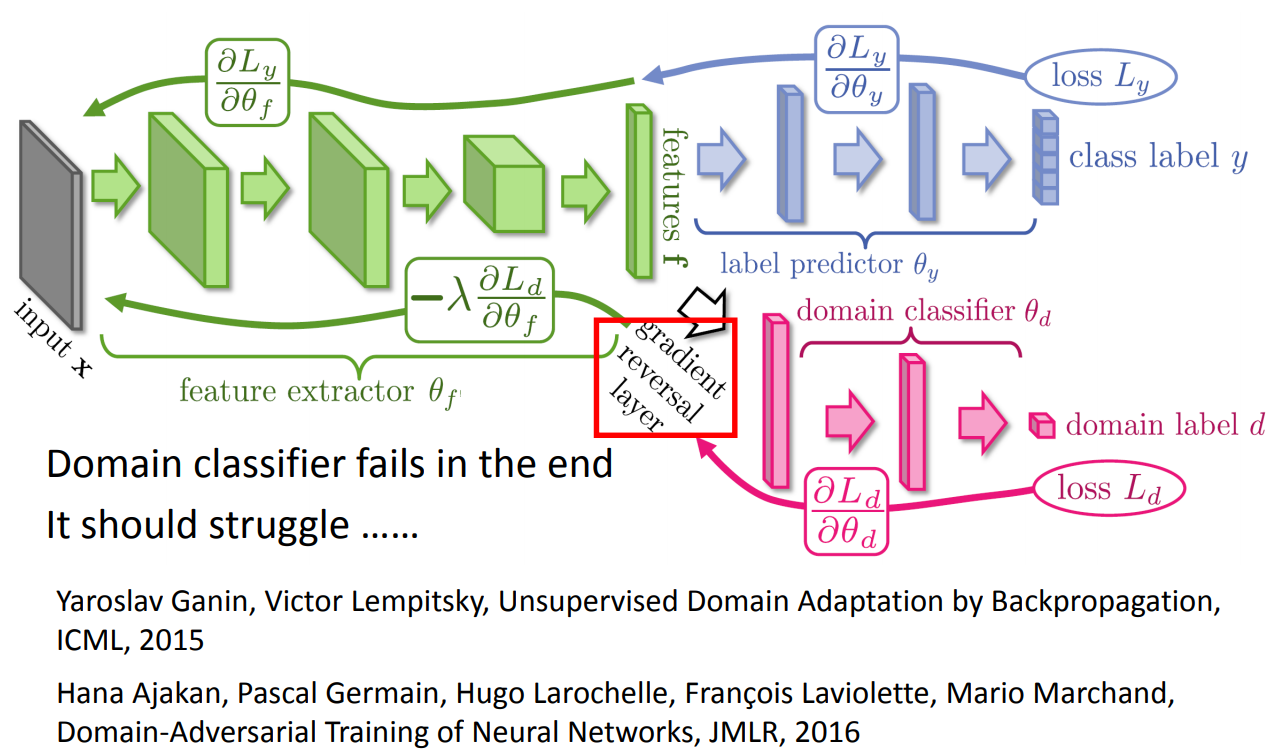
另一种学习方法是zero-shot learning。跟domain adversarial learning的区别就是,zero-shot learning的task是不一样的,而domain adversarial learning的task是一致的,所以后者会希望将feature做到一起去。
那么zero-shot learning要如何实现呢?因为我们要做的目标是不一致的,那我们就需要让机器学习到最基本的单位。比如说我们有一个区分猫狗的模型,想做区分驴和马的模型,我们希望机器学到的是动物有没有尾巴,有没有毛茸茸的,有没有爪子这样。
但是这样做的前提是,我们要有一个这样的特征库,也就是说,我们要有一个数据库记录的是猫是不是有尾巴,是不是毛茸茸,是不是有爪子,并将这个作为训练目标。那如果我们连这个数据库都没有,怎么办呢?这里有一个非常trick的做法,我们可以用word2vec生成的向量来作为y训练。
那另外一个zero-shot learning的方法是把所有数据的feature都embedding到一个空间中:
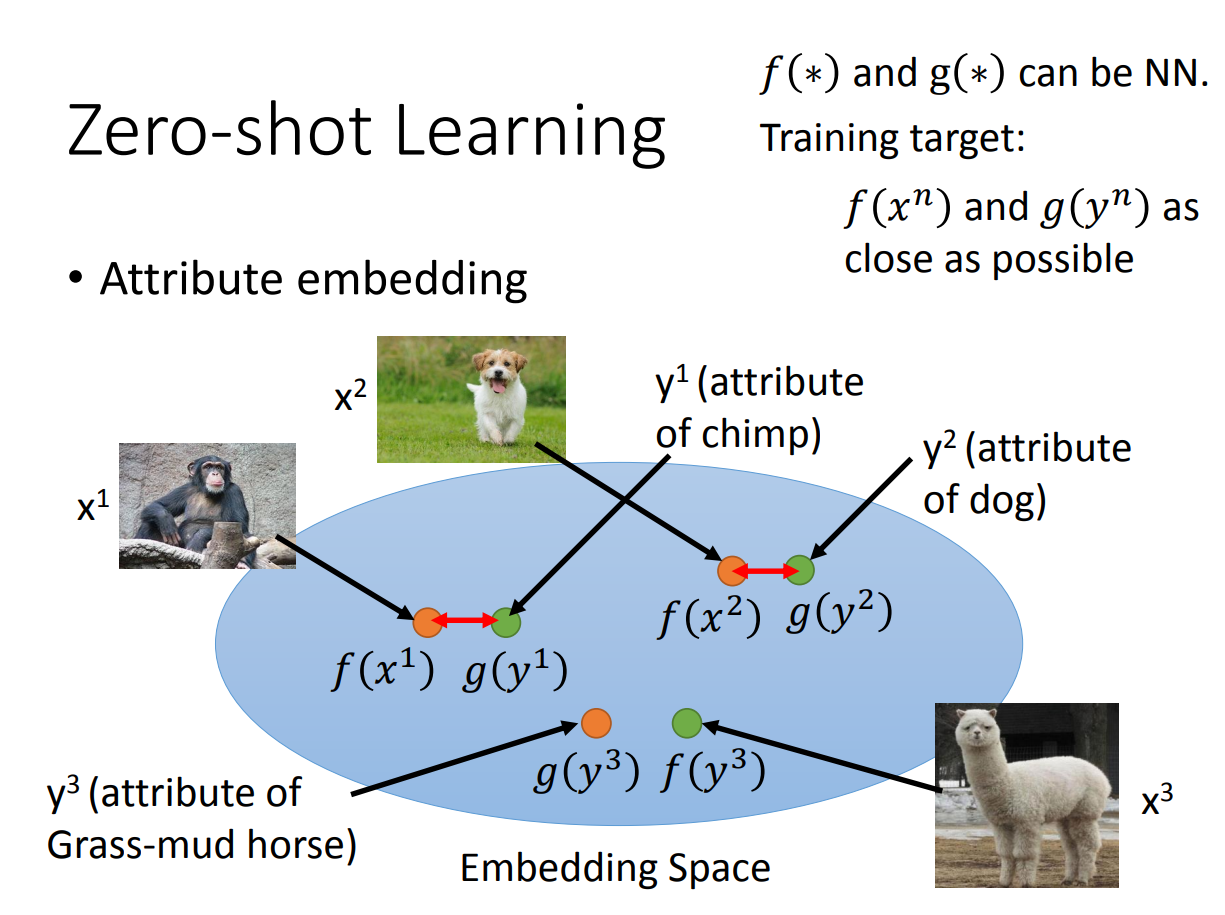
这里希望学到的就是图片直接抽取的特征\(f(*)\)和通过attribute学习到的vector \(g(*)\)越接近越好。同样的,如果没有attribute,我们就用word2vec来替代attribute。
那这里又有一个问题,如果直接计算两个vector的点内积这样训练的话,\(f(*)\)和\(g(*)\)都变成0就完全一样了。所以我们需要加一点限制:
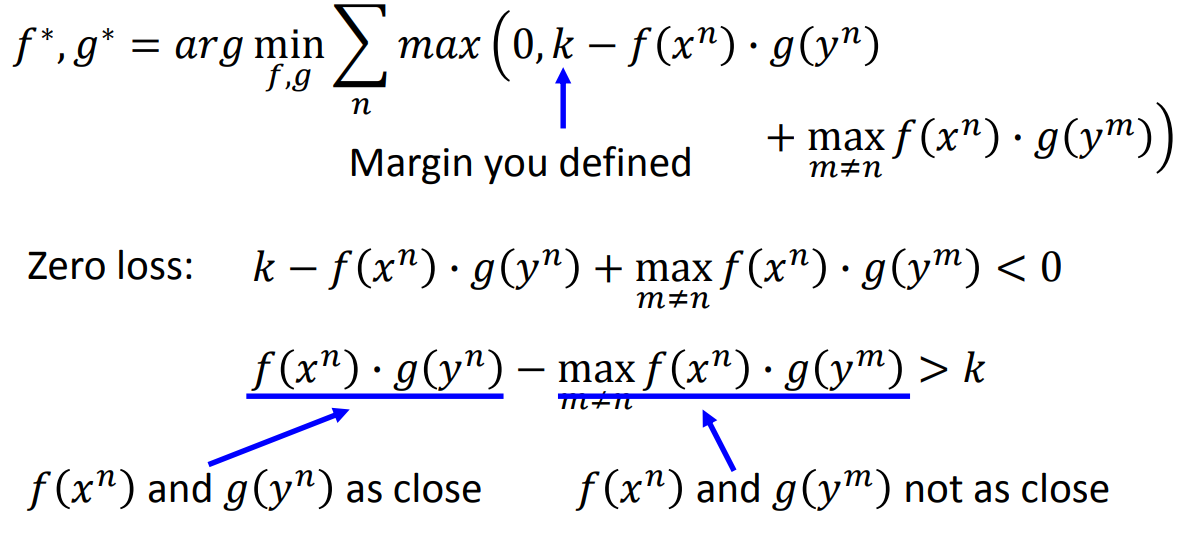
那我们这里加的限制是,同一个类别的两个vector越近越好,两个不同类别的vector越远越好。这样就可以保证所有的vector不会都堆到0这个地方,另外也不会导致几个类别离得太远。
那其实也可以用现成的模型,然后将新的数据扔进去做分类。这个方法叫• Convex Combination of Semantic Embedding。如下:
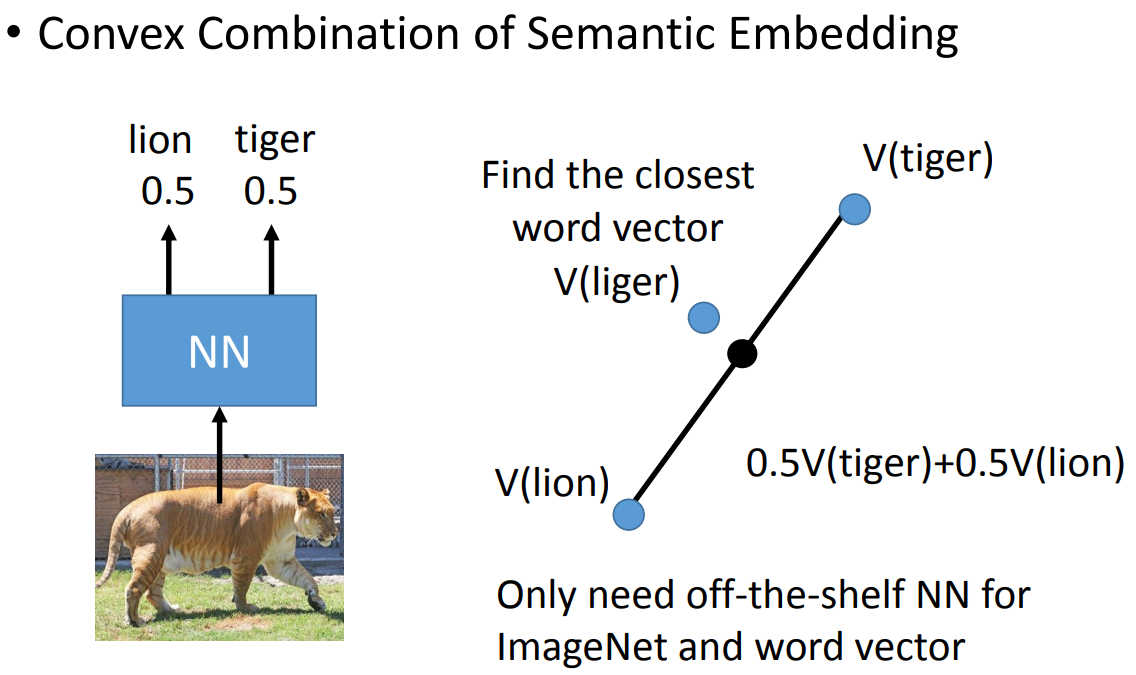
整个做法就是这边把图片放进来,然后预测出来一半是狮子,一半是老虎,然后把老虎跟狮子的词向量做加权平均,找一个离加权平均值最近的向量就是最终的label。这个实验可以看这篇文章https://arxiv.org/pdf/1312.5650v3.pdf。
最后的一开始的那个表格内剩下的两个格子没有细讲,都是一笔带过,这里也就不多说啥了。感觉那两个才是真的transfer learning,毕竟还有戴文渊的文章。后面好好研读吧。
