生成模型,可以用来做炼金术师的禁忌之术,人体炼成。
生成模型基本上有三大类做法,一种是基于序列的预测,比如可以用RNN。一种是基于deep auto-encoder。最后一种就是现在最火的GAN。
基于序列预测
基于序列预测的方法听上去很像w2v,就是把每一个pixel看做是一个词,然后用训练的时候就像是训练w2v一样。所以整个训练的过程就是:
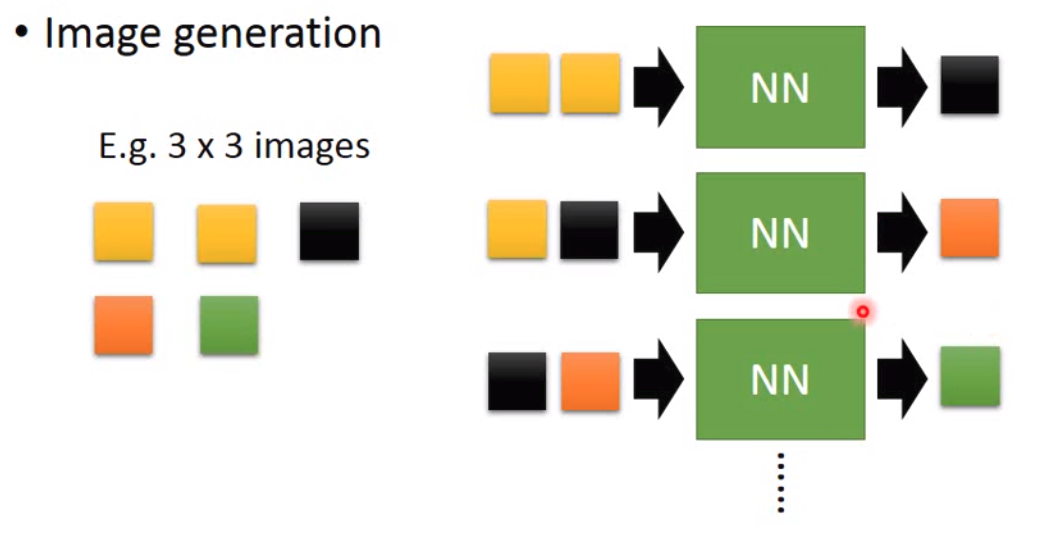
那这种方法有一个很强大的应用就是做WaveNet。
auto-encoder
前几节课有讲过一个auto-encoder,实际操作的时候就是在抽取pattern,然后再还原回原来的样子。所以原理上来说其实我们可以输入一个vector,然后通过decoder输出一个新的结果。
但是用auto-encoder有一个很大的问题,那就是很多时候,其实我们输入的vector不会得到很好的结果。因为我们放进去的vector是decoder没见过的code。这个就很好理解,我们可以想象一个加密解密过程。我们将原文加密成密文,接收方用密钥解密得到原文。那现在我们用了另一个加密方法加密得到的密文发过去,接收方就没法解密了。
基于上面的情况,我们就有了新的一个加强版auto-encoder,就是VAE。
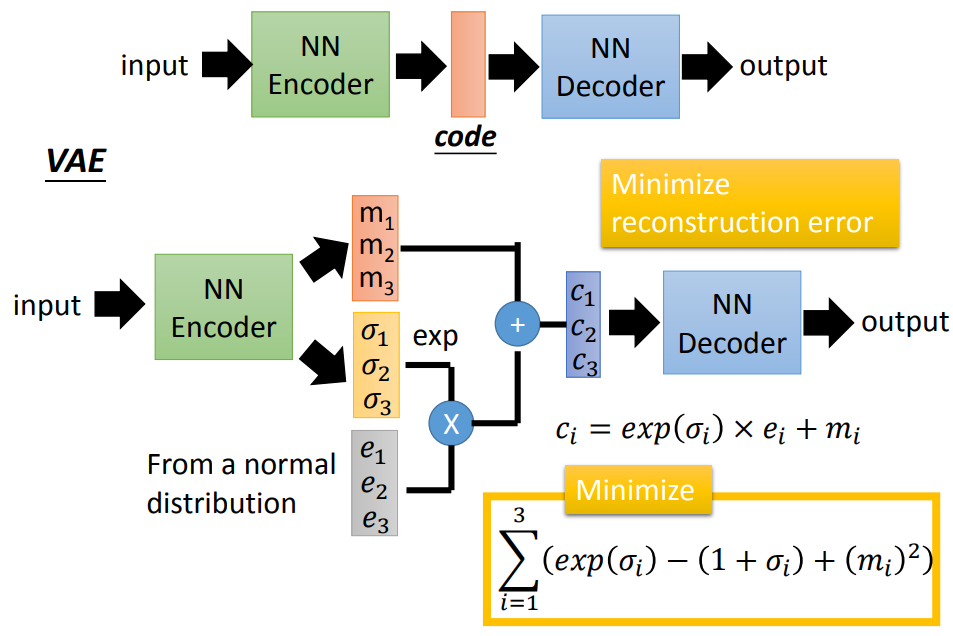
那这里我们有两个minimize的方向,一个是跟auto-encoder一样的minimize reconstruction error,另一个就是上图右下角一个minimize的项目。简单来说VAE自动学习了两个noise,一个是\(\sigma\)另一个是\(e\)。\(\sigma\)其实是机器自己学习出来的noise,那如果不做这样的限定的话,出于最小化reconstruction error的目的,我们就可以让\(\sigma\)变得非常大,那这样的话noise就变得很小。noise越小,那么这个模型就回到了原来的auto-encoder的模型上去了。那加noise的目的直观来讲,可以认为是给了一些可能性让模型来生成没见过的密文。
GAN
GAN本身是一个很有意思的设计。GAN设计了两个网络,一个网络是generate网络,用来生成模型,另外一个网络是discriminator网络,用来分辨两个图是模型生成的还是真实的。
那这样设计的目的其实也是很明显的,generate网络的目的是去尽可能逼近真实分布,就像下面的样子:
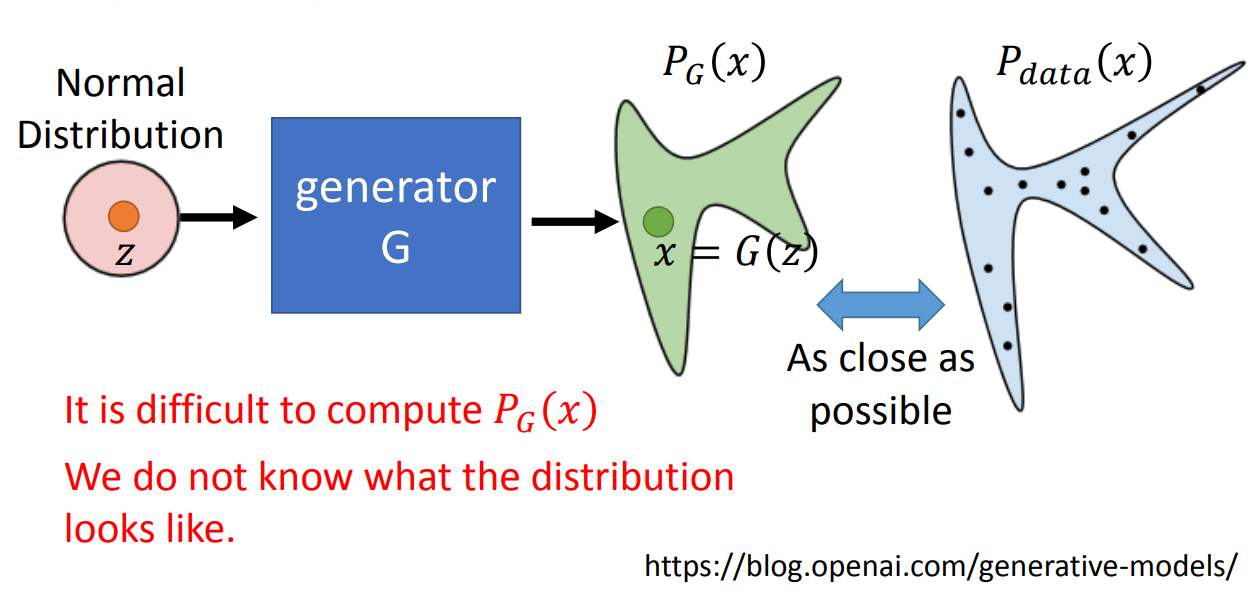
那我们要去衡量两个分布是否相近是很难的,所以就设计了一个分类器来分辨。当分类器分不清到底是真实图片还是生成的图片的时候,那么我们就可以认为两个分布很接近了。
那整个的训练过程就像是一个进化的过程。一开始,第一代generate模型生成的结果会被第一代的discriminator模型区分,然后更新参数,第二代generate模型生成的结果被第二代discriminator模型区分。一直迭代到discriminator模型分不清为止。
GAN一开始是非常难训练的,因为GAN一开始设计的衡量方法是JS divergence。JS divergence在两个分布没有overlap的时候,计算出来的结果都是一样的,所以模型本身不知道自己是不是训练的越来越好。后来WGAN是一个新的解决方案,将JS divergence改为Wasserstein distance。Wasserstein distance是一个可以衡量两个分布是不是越来越接近的方法,因此用WGAN就可以让模型知道是不是训练效果越来越好。在NLP里面,因为语言不是连续分布,所以WGAN就可以用来生成语句,而原来的GAN就不可以。这两个的差别就像下图:

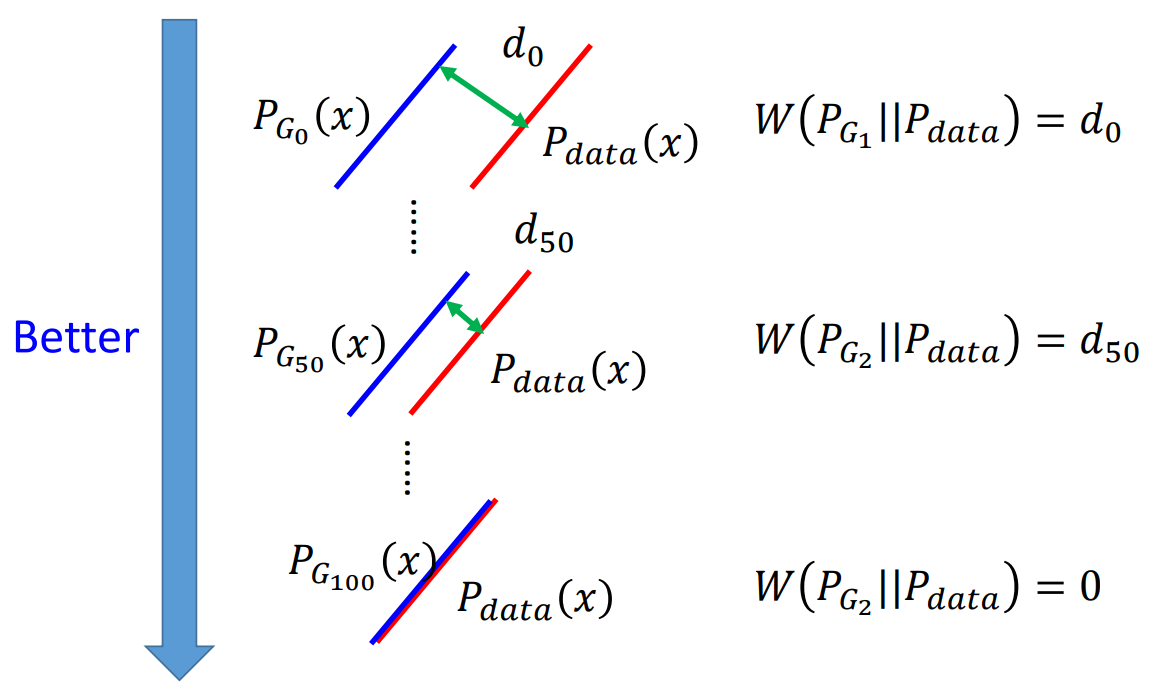
那GAN有各种各样的变种,具体还是要多读论文。
这个都是一些简单介绍,具体的原理还是要读原来的paper,推公式。留个大坑,先把课程上完。括弧笑。
