Word embedding
Word embedding
Word embedding之前比较流行的叫法是word vector。那其实要理解word embedding之前我们需要回过头看一下到底之前是如何做这个操作的。
在很古老很古老的时候,如果我们要用向量表示一个单词,只能用一个one-hot的方法来表示,也就是一串很长很长的0-1向量。这个很长很长的向量长度跟单词的数量一样多。比如说,我们有10w个英文单词,那么这个向量就有10w维,然后给每个词在这个向量里面找个位置标记为1,其他位置标记为0,这样就得到了最原始的词向量。
但是这个向量不用想都知道,一个很突出的问题,太大了。另外有一个很大的问题就是这样的表示,没有办法表达出词语的含义。所以word embedding做的事情就是将这个很长很长的向量,压缩到低维。比如现在最常用的100-200维之间。
那word embedding实际上可以做到通过读海量的文档内容,然后理解单词的意思。比如 The cat sat on the pat和The dog sat on the pat这两句话,cat和dog是接近的。
那做到word embedding有两种做法。第一种是计算词语的共现次数,另一种是通过上下文的方法去做预测。
词语共现
这种做法的代表是Glove Vector。这种方法是假设两个经常共同出现的词,他们的向量应该是类似的。
用其实就是\(V(w_i) \cdot V(w_j)\)和他们共现的次数\(N_{ij}\)相关。
基于预测
基于预测的word embedding做法一般是按照输入的单词,预测输出的单词。就像下图表示的:
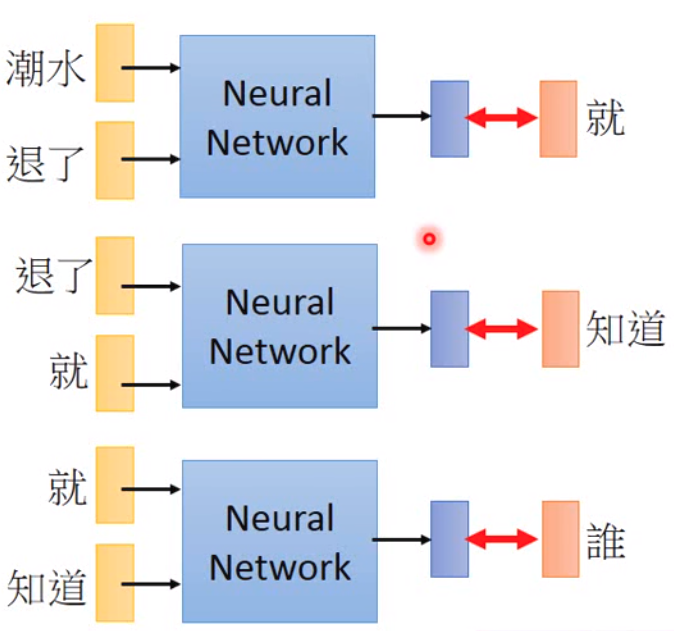
这样的方法可以用来文本接龙,当然也可以用于语音辨识上面。
那实践上,我们做的事情就像下面:
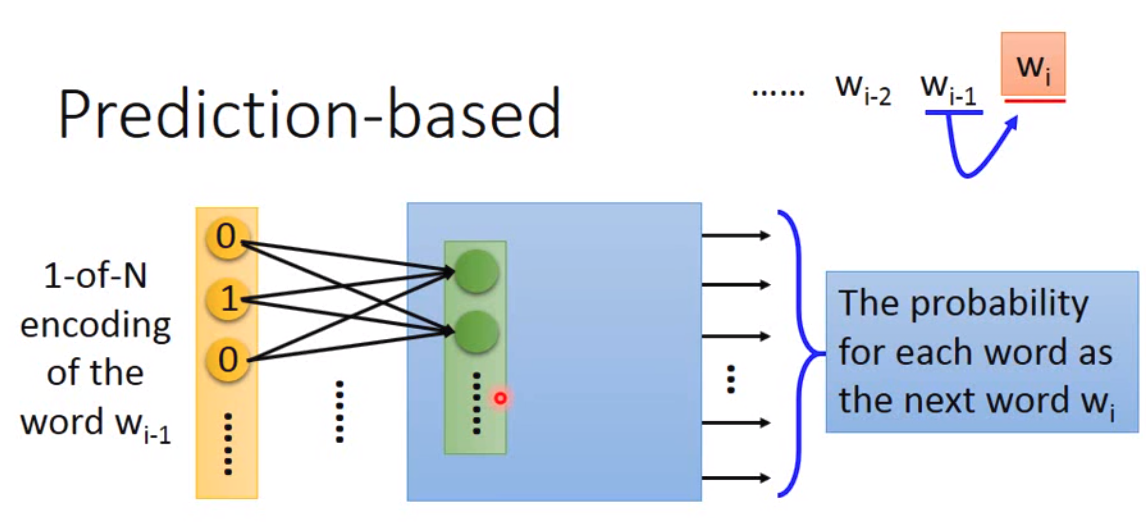
我们实际上得到的word vector就是中间绿色层的output。那理论上而言,我们在这一层得到的vector在某种程度上,可以体现一定程度的语义。因为同样类型的词,后面需要predict的词应该也是类似的。
那我们做predict-based approach的时候,我们实际使用的神经网络仅有一层,而且激活函数是linear的。那这么做的原因其实是因为作者实验发现,单层网络就可以做到很好的效果,同时,因为我们需要训练海量的数据,因此单层的网络速度上可以做到更快。
现在我们直接考虑这个模型,我们在训练模型的时候,其实会碰到一个很明显的问题,那就是我们做linear transform的时候,每一个input layer需要乘上一个非常大的weight matrix。所以实践上,我们会用共享参数的方法:
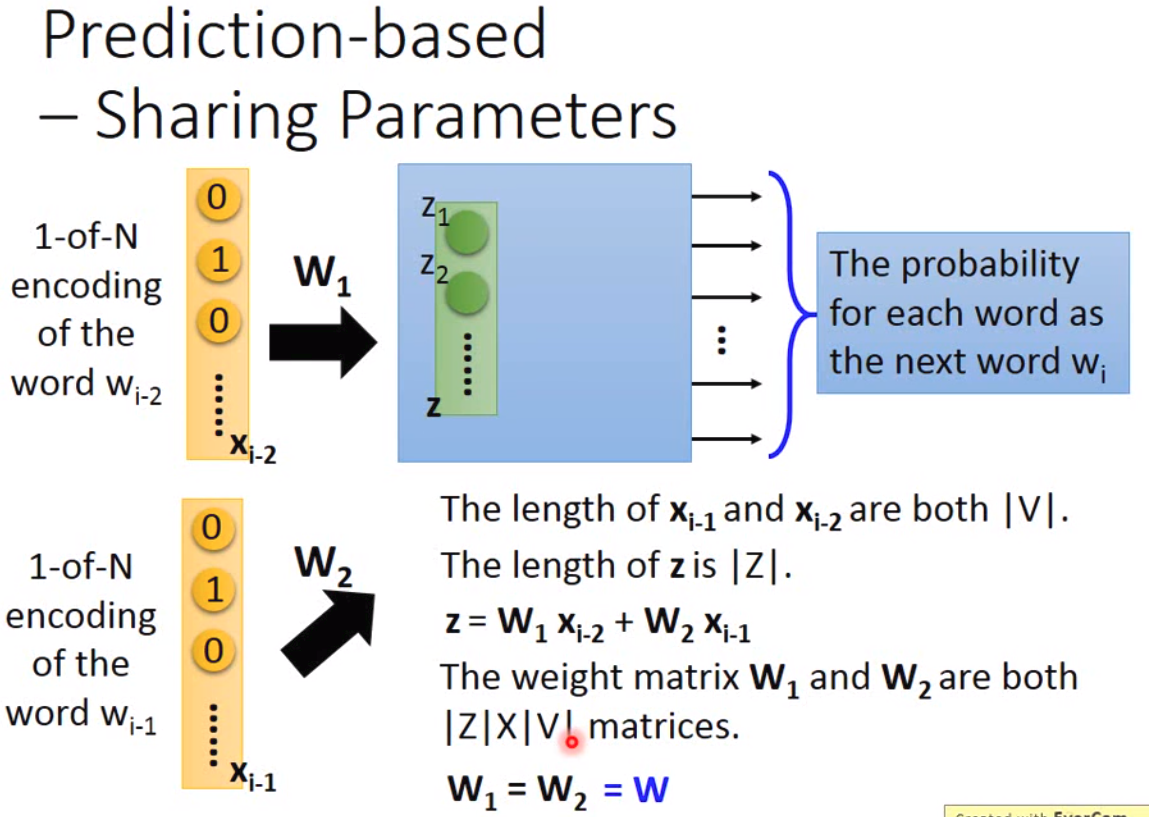
那我们用这样的方法有什么好处呢?第一是我们不需要训练非常多很大的weight matrix,另外同一个word不会得到不一样的vector。训练模型的方法一般有两种,一种是cbow,一种是skip-gram。cbow就是用上下文猜中间的词,skip-gram是按照中间的词猜上下文。两个结构大概如下:
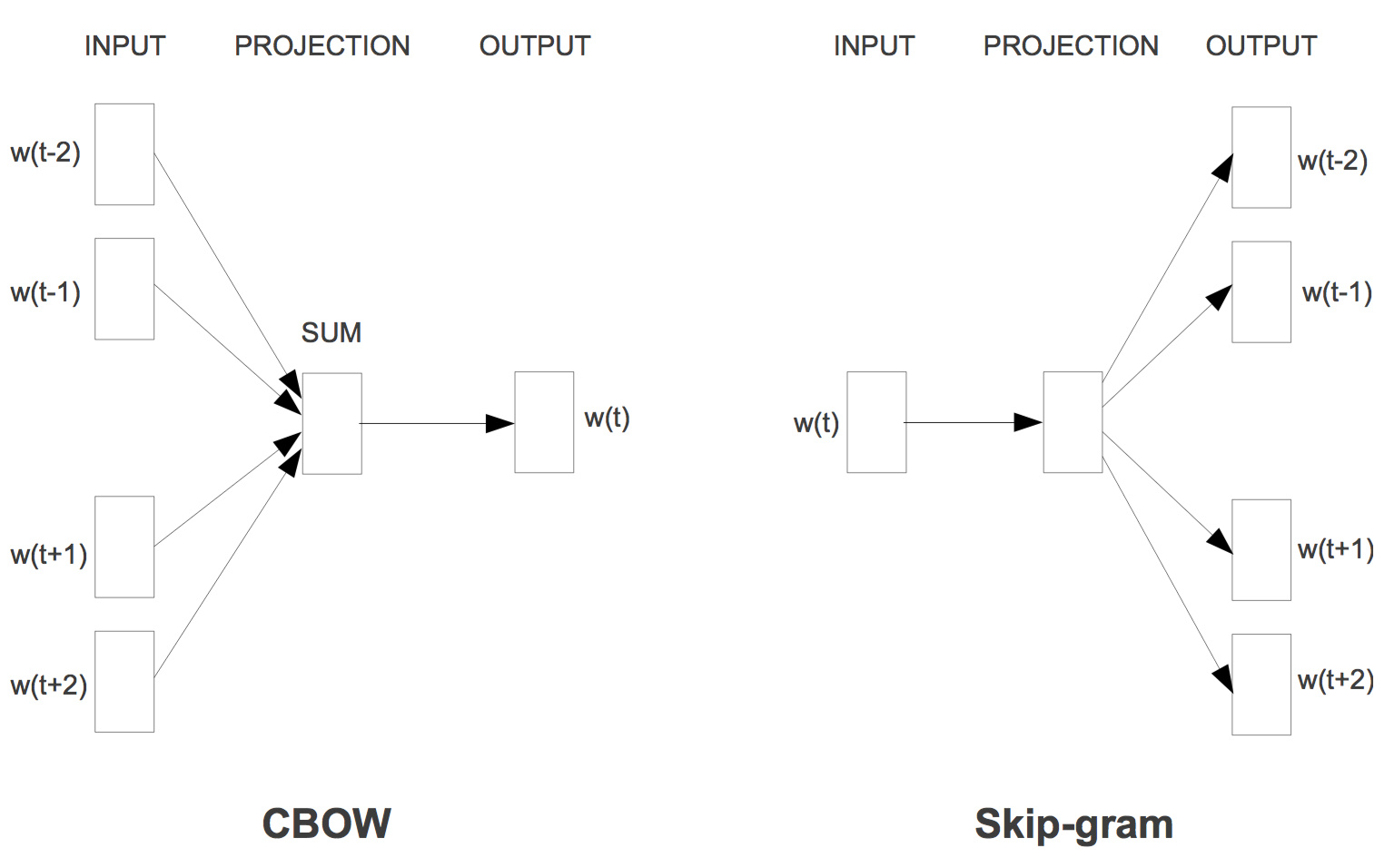
不过坦白说,课程里面讲的比较少,也不是很深。网上流传最广的是有道团队写的一篇。不过渣渣表示,二十几页拆源码的看起来好累。实践上有很多trick的地方,比如说最后的loss function用的不是softmax,现在用的比较多的是nce。文章及代码可以参考项亮的专栏或者简书。或者参考TensorFlow的一个实现[1],代码看起来相对简单一点点。TensorFlow这个实现可以比较清楚看懂训练数据是如何准备的,之前一直没搞懂的就是不知道训练数据是怎么准备的。不过这个博客里面说用的是cbow,我看了源码,感觉博主写的不是cbow,就是根据上一个词猜下一个词。
最好理解的就是训练数据在准备的时候需要准备两份,第一份是词表以及词频等数据,另一个就是每个sentence,这样才能找到每个词的上下文。然后根据不同的模型决定如何设计feature和target。
- 1.https://fangpin.github.io/2016/08/22/word2vec ↩︎
