基于CNN的中文验证码识别
出于对深度学习的实践目的,选择了CNN这一古老的工具以及OCR这个古老的问题。之前用AdaBoost,通过二值化,字符分割,再进行字符识别。准确率么是惨不忍睹,不过练练手还是可以的。
传统方法上最难的是除噪和分割,尤其是碰到字符粘连,干扰线等等。
深度学习的一个好处就是可以做end-to-end的学习。参考项亮大神的博客 [1]
把OCR的问题当做一个多标签学习的问题。4个数字组成的验证码就相当于有4个标签的图片识别问题(这里的标签还是有序的),用CNN来解决。
把OCR的问题当做一个语音识别的问题,语音识别是把连续的音频转化为文本,验证码识别就是把连续的图片转化为文本,用CNN+LSTM+CTC来解决。
作为深度学习门外汉,这里就先做CNN的版本。刚好项亮大神用的是MXNet,而我对MXNet又有蜜汁好感,就在其基础上做了一些修改,变成自己的版本。
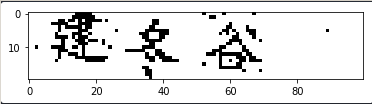
首先需要搞定数据。深度学习对数据量的饥渴是很可怕的,我的目标是尽可能模拟新浪的验证码:
为了方便生成数据,其实我还是对图片做了二值化,转化之后的图片是这样的:
通过这样处理,我在生成数据的时候就不需要模拟背景色。另外新浪很友好没加干扰线,所以这一步也省了。
参考另一篇Python生成中文验证码的博客 [2]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class RandomChar (): """用于随机生成汉字""" @staticmethod def Unicode (): val = random.randint(0x4E00 , 0x9FBF ) return chr (val) @staticmethod def GB2312 (): head = 0xB0 body = random.randint(0xA1 , 0xAA ) val = (head << 8 ) | body str = "%x" % val str = codecs.decode(str , 'hex' ) str = str .decode('gb2312' ) return str , val
首先是随机生成汉字。汉字字数其实非常多,尤其是Unicode编码的,所以这里我选择了GB2312的一级汉字,一共会有3755个。为了模型跑得快一点,这里放了前10个汉字,编码从B0A1到B0AA。
然后是生成验证码图片:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 class ImageChar (): def __init__ (self, fontColor=(255 , 255 , 255 size=(100 , 20 fontPath='ukai.ttc' , bgColor=(0 , 0 , 0 fontSize=20 ): self.size = size self.fontPath = fontPath self.bgColor = bgColor self.fontSize = fontSize self.fontColor = fontColor self.font = ImageFont.truetype(self.fontPath, self.fontSize) self.image = Image.new('RGB' , size, bgColor) def drawText (self, pos, txt, fill ): draw = ImageDraw.Draw(self.image) draw.text(pos, txt, font=self.font, fill=fill) del draw def drawTextV2 (self, pos, txt, fill ): image = Image.new('RGB' , (20 , 20 ), (0 , 0 , 0 )) draw = ImageDraw.Draw(image) draw.text((0 , -3 ), txt, font=self.font, fill=fill) w = image.rotate(random.randint(-10 , 10 ), expand=1 ) self.image.paste(w, box=pos) del draw def randPoint (self, num ): (width, height) = self.size draw = ImageDraw.Draw(self.image) for i in range (0 , num): draw.point([random.randint(0 , width), random.randint(0 , height)], (255 , 255 , 255 )) del draw def randChinese (self, num ): gap = 5 start = 0 label = [] while len (label) < num: try : char, val = RandomChar().GB2312() except UnicodeDecodeError: continue x = start + self.fontSize * \ len (label) + random.randint(0 , gap) + gap * len (label) self.drawTextV2((x, random.randint(-3 , 2 )), char, (255 , 255 , 255 )) label.append(s.index(val)) self.randPoint(18 ) return label def save (self, path ): self.image.save(path)
原来代码里面的旋转其实并没有真正生效,因此修改成了
1 2 3 4 5 6 7 def drawTextV2 (self, pos, txt, fill ): image = Image.new('RGB' , (20 , 20 ), (0 , 0 , 0 )) draw = ImageDraw.Draw(image) draw.text((0 , -3 ), txt, font=self.font, fill=fill) w = image.rotate(random.randint(-10 , 10 ), expand=1 ) self.image.paste(w, box=pos) del draw
这里要注意的是,原来博客里实现的是RGB的三通道,但是二值化后单通道就可以了,所以后面再压回单通道就好了。另外因为旋转后会有黑边,所以我改成了生成黑底白字。实现后生成的图像是这样婶的:
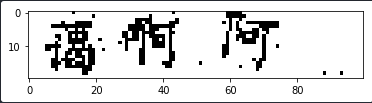
再用255减一下就可以了:
乍一看还是有点像的。
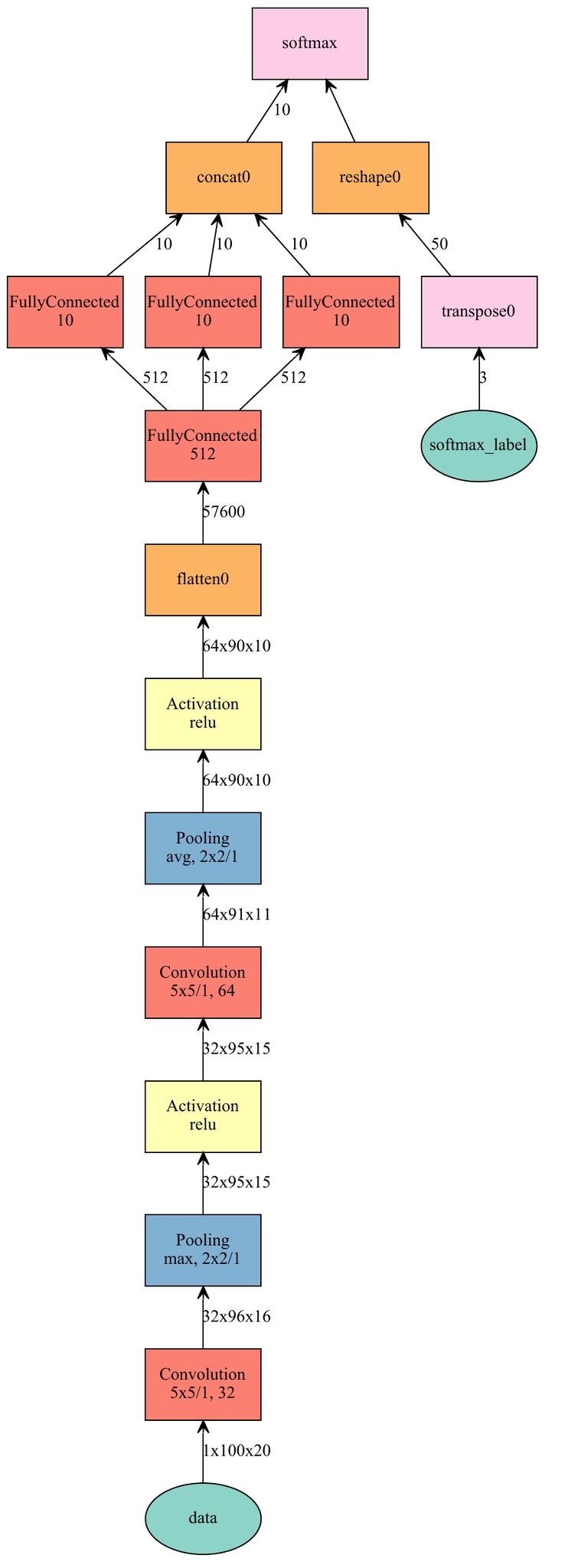
接下来就是根据MXNet的规则开始搭建网络。首先需要定义Data Iterator,防止爆内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class OCRIter (mx.io.DataIter ): def __init__ (self, count, batch_size, num_label ): super (OCRIter, self).__init__() self.batch_size = batch_size self.count = count self.num_label = num_label self.provide_data = [('data' , (batch_size, 1 , 100 , 20 ))] self.provide_label = [('softmax_label' , (self.batch_size, num_label))] def __iter__ (self ): for k in range (int (self.count / self.batch_size)): data = [] label = [] for i in range (self.batch_size): ic = ImageChar() num = ic.randChinese(self.num_label) tmp = np.array(ic.image.convert("L" )) tmp = 255 - tmp tmp = tmp.reshape(1 , 100 , 20 ) data.append(tmp) label.append(np.array(num)) data_all = [mx.nd.array(data)] label_all = [mx.nd.array(label)] data_names = ['data' ] label_names = ['softmax_label' ] data_batch = OCRBatch(data_names, data_all, label_names, label_all) yield data_batch def reset (self ): pass
这里一定要注意: 1 2 self.provide_data = [('data' , (batch_size, 1 , 100 , 20 ))] self.provide_label = [('softmax_label' , (self.batch_size, num_label))]
然后这里定义了一个简单的卷积网络:
三个Full Connect层用来做三个汉字的识别,然后Concat回去。这有就能同时学习三个汉字。
接下去就是让机器开始训练。训练过程中也有一些比较尴尬的情况发生。我用的是GTX 1080,CUDA 8.0,cuDNN 5的配置,训练的过程中发生了一件非常离奇的准确率跳崖事件。在learning rate为0.001的时候,一开始看着还正常,但是中间发生了从82%掉到40%的情况,好在后面又爬起来了。
由于之前的epoch都在10以内,最后下了狠心干脆一样的参数跑100个epoch看是不是真的自杀完活不过来了。开了后台跑,结果自杀现象又消失了。中间有一次跳崖,但爬起来了。 这个 。
那么问题来了,自杀到底是Epoch不够还是learning rate太大?
2017-04-25更新: 我做了一个282字的识别,learning rate设定为0.0005的情况下,在32个epoch时候跳崖自杀,39个epoch爬回来,40个epoch又自杀,从此一蹶不振。于是被我提前掐死了。但是当我将lr改到0.0001,到了168个epoch,已经到了97%了。所以目测跳崖自杀是lr太大了。
不过这种防止自杀的手段是有明显短板的,那就是lr太小收敛很慢。如果跟我一样仅有一块1080卡,然后像我多放几个filter和hidden,速度就是上图,呵呵哒了。

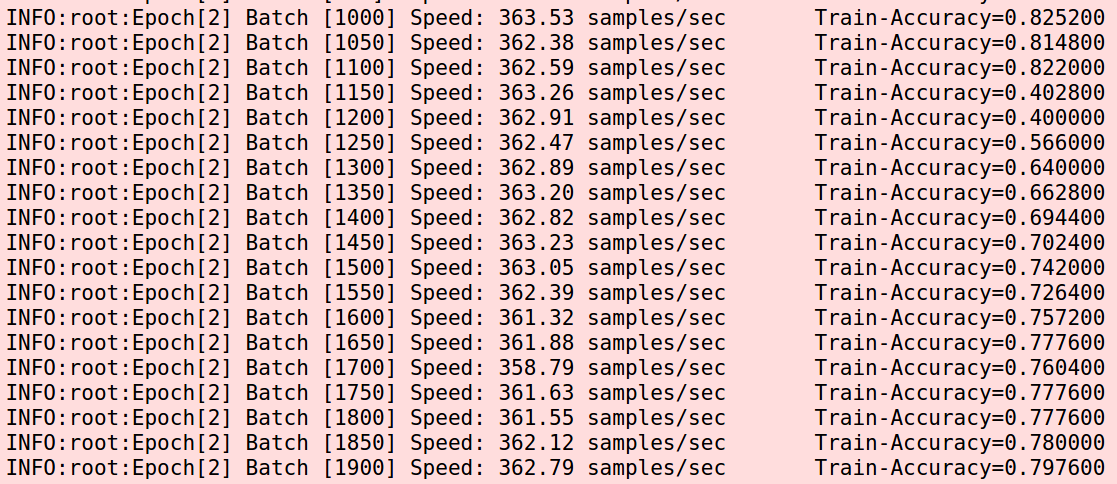 但是后面突然掉到了0,接着就再也爬不起来了。我原以为是偶然,掐掉重跑,又发生了这个事情。而且发生的更早。
但是后面突然掉到了0,接着就再也爬不起来了。我原以为是偶然,掐掉重跑,又发生了这个事情。而且发生的更早。 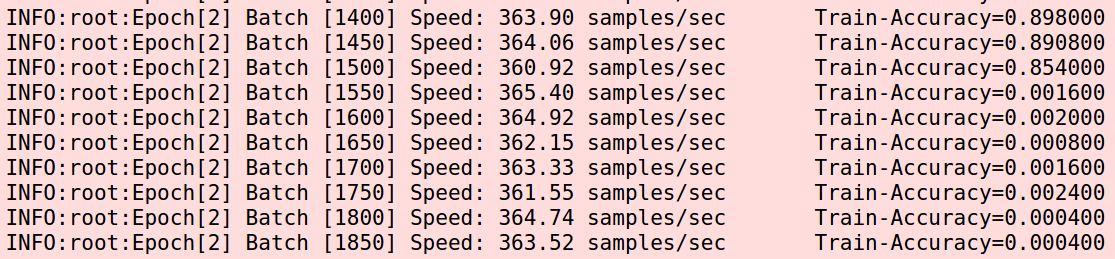 我又怀疑是learning rate设大了,于是改为0.0005,好吧,这已经小的有点逆天了。
我又怀疑是learning rate设大了,于是改为0.0005,好吧,这已经小的有点逆天了。 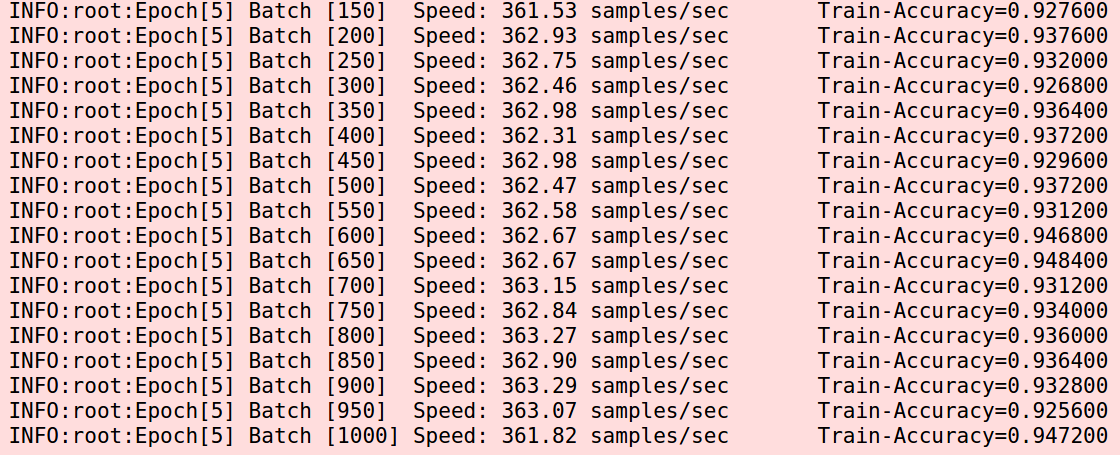 一切看起来都很好。而且准确率比0.001还高了一点。中间也会发生跳崖,但是都爬起来了。意外很快发生,下一个epoch快结束的时候又自杀了。
一切看起来都很好。而且准确率比0.001还高了一点。中间也会发生跳崖,但是都爬起来了。意外很快发生,下一个epoch快结束的时候又自杀了。 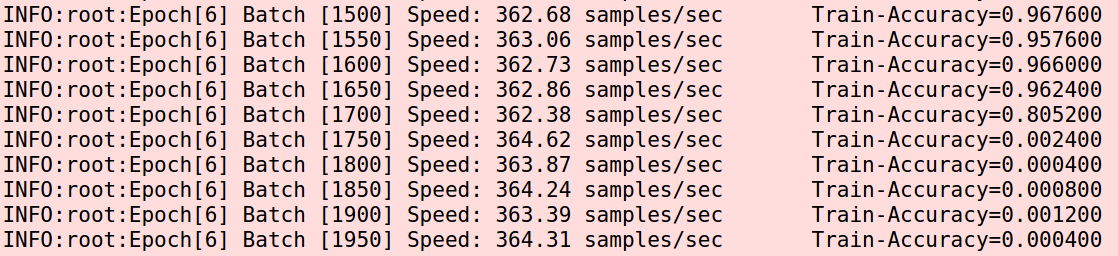
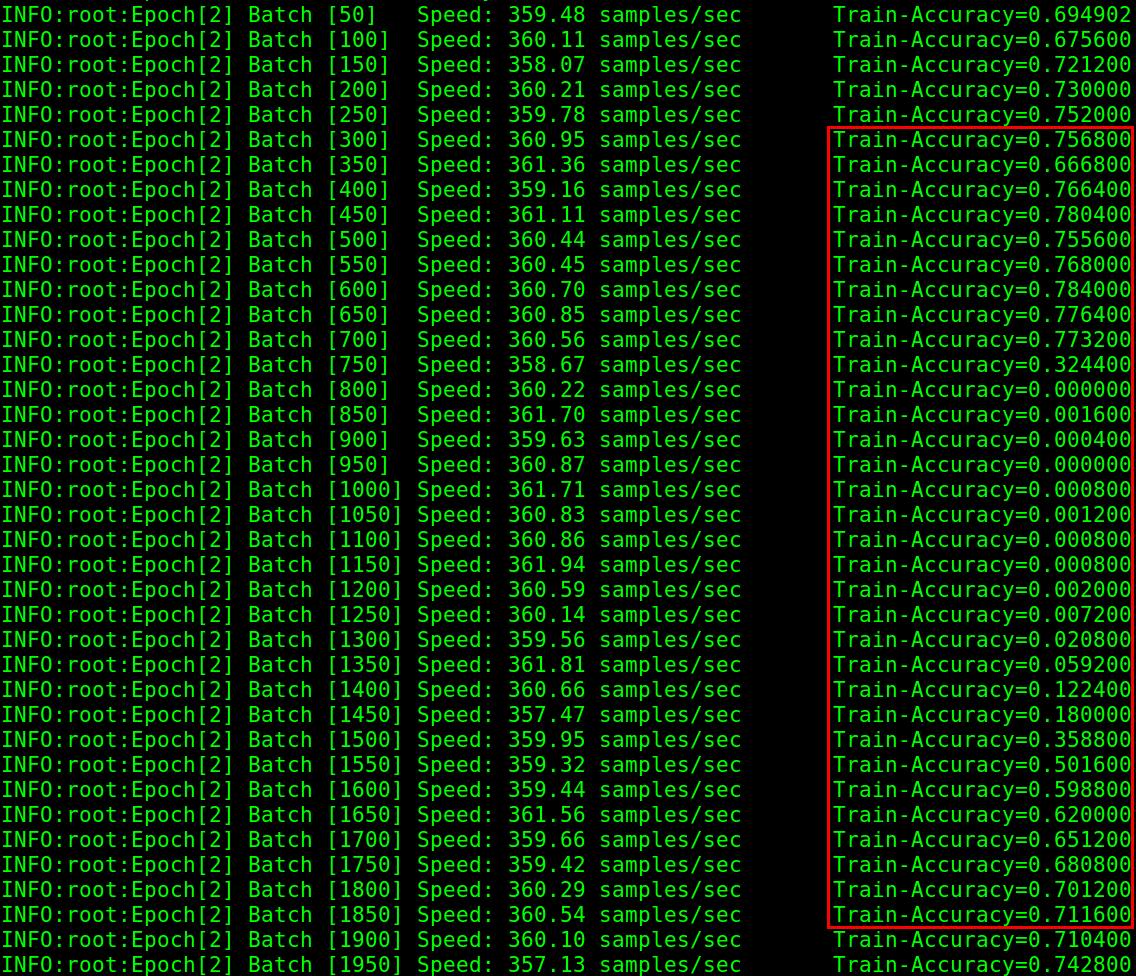 大概十来个Epoch后基本上就刷到了90%以上,后面不但没有再自杀,甚至出现了100%的情况。
大概十来个Epoch后基本上就刷到了90%以上,后面不但没有再自杀,甚至出现了100%的情况。 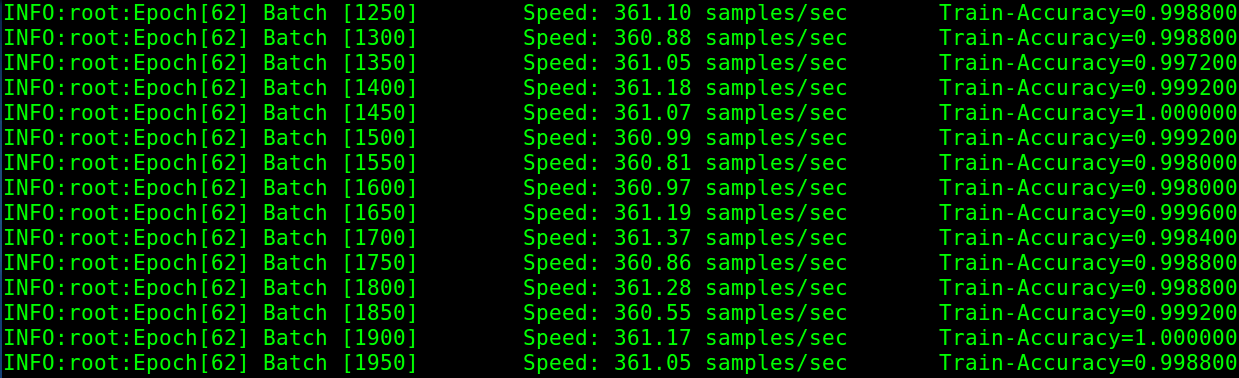 哪怕到了最后也一切安好。
哪怕到了最后也一切安好。 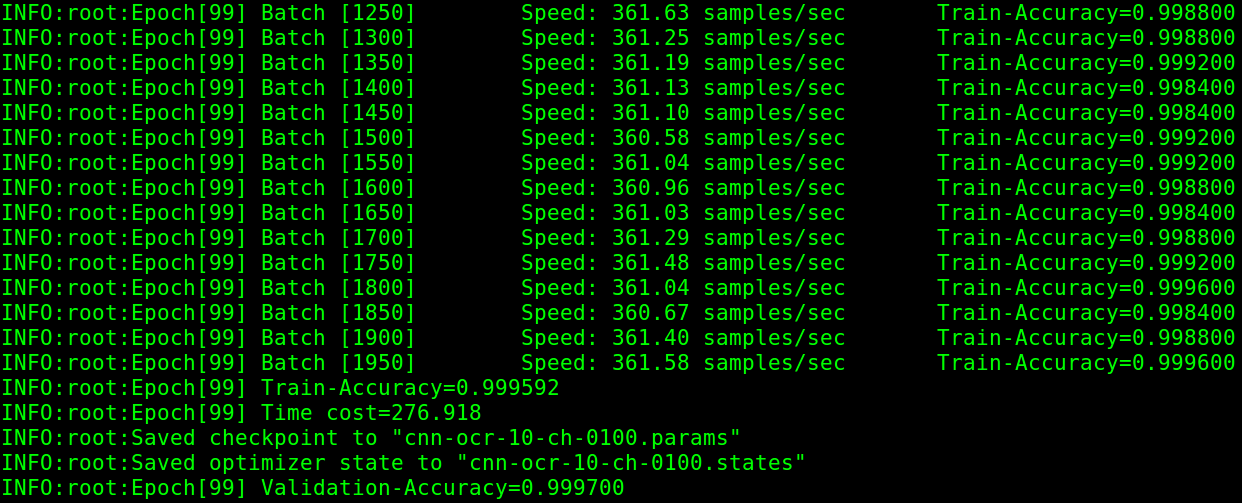 完整的log可以看这个。
完整的log可以看这个。
